

“Fairly than depend on a courtroom’s coin flip as as to if using the copyrighted work to coach LLMs is honest use, it could be higher to develop a licensing mechanism that rewards publishers with out subjecting AI builders to large statutory damages.”
ChatGPT and related generative synthetic intelligence (AI) instruments depend on massive language fashions (LLMs). LLMs are fed large quantities of content material, corresponding to textual content, music, images and movie, which they analyze to find statistical relationships amongst these inputs. This course of, describe as “coaching” the LLMs, offers them the flexibility to generate related content material and to reply questions with seeming authority.
The enterprise neighborhood, and society at massive, appears satisfied that AI powered by LLMs holds nice promise for will increase in effectivity. However a number of lawsuits alleging copyright infringement may create a drag on improvement of LLMs, or worse, tip the aggressive stability in direction of offshore enterprises that take pleasure in the advantages of laws authorizing textual content and knowledge mining. Rather a lot appears to hold on the query of whether or not LLM coaching includes copyright infringement or as a substitute is a good use of copyrighted content material.
In only one instance of the litigation that this has spawned, the New York Instances Firm recently sued OpenAI and Microsoft, accusing it of large copyright infringement within the coaching of the LLM underlying ChatGPT. This litigation, and different instances prefer it, might drive the courts to resolve the query of honest use. In the event that they conclude that LLM coaching is honest use, then the copyright house owners will get nothing from this exploitation of their content material. In the event that they don’t discover honest use, then the LLM house owners could also be responsible for billions of {dollars} in statutory damages.
This winner-take-all final result based mostly upon the subjective query of honest use (see, e.g., the bulk and dissenting opinions in Warhol v. Goldsmith) calls into query the adequacy of the present authorized regime and whether or not, within the context of the event of AI, the present copyright system will “promote the Progress of Science and helpful Arts” or will unduly hinder it.
Background
Newspapers should present their subscribers with digital entry to their content material as a way to stay aggressive. The New York Instances, in paragraph 45 of its complaint in opposition to OpenAI, says that on common about 50 to 100 million customers interact with its digital content material every week. Of these, almost 10 million are paid subscribers who obtain solely the digital model of the Instances.
To supply its content material, the Instances employs about 5,800 individuals, of whom about 2,600 are straight concerned in journalism operations. Criticism at ¶38. The Criticism says that “[t]he Instances does deep investigations—which normally take months and generally years to report and produce—into complicated and necessary areas of public curiosity. The Instances’s reporters routinely uncover tales that might in any other case by no means come to mild.” Criticism at ¶33.
The perfect authorized safety out there to the Instances is copyright, which the Instances takes severely, submitting copyright registrations of its newspaper day by day. Sadly for the Instances, copyright protects the wording used to explain a information occasion however not the information itself. Because the US Copyright Workplace has said, “[o]ne elementary constraint on writer’s capacity to forestall reuse of their information content material is that information and concepts are usually not copyrightable.”
The Instances already makes its content material out there for license by way of the Copyright Clearance Heart. A CCC license to put up a single Instances article on a industrial web site for a 12 months prices a number of thousand {dollars}. Criticism at ¶51. At these costs, LLM house owners are prone to keep away from utilizing the content material of the Instances, preferring to take their probabilities in courtroom.
The Use of Instances Content material to Prepare ChatGPT.
The Instances grievance cites disclosures made by OpenAI concerning the coaching units utilized by early variations of ChatGPT. These disclosures establish the Instances because the 5th most vital supply used to coach ChatGPT. Criticism at ¶85. Proving that that is nonetheless the case for the present model, an attachment to the grievance offers 100 examples of ChatGPT 3.5 spitting out actual or almost actual copies of articles that appeared within the Instances. Exhibit J to Criticism.
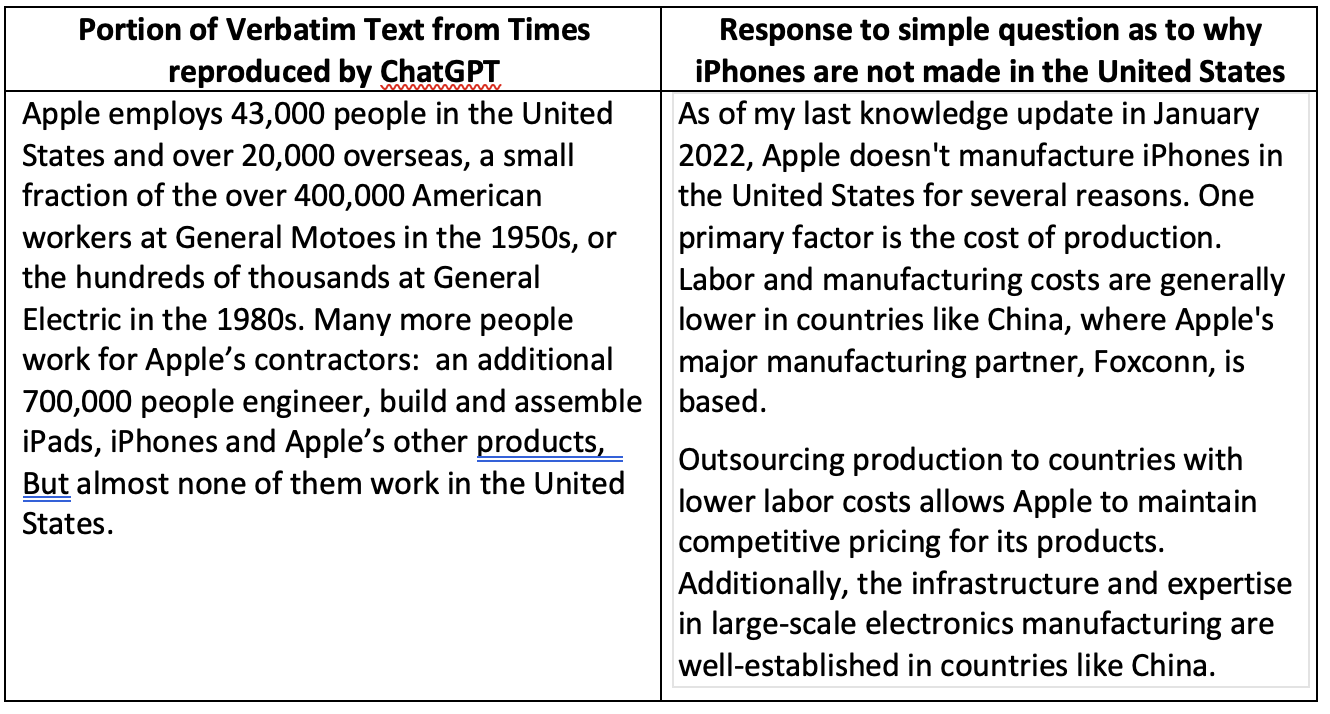
The primary instance within the Instances’s attachment includes an article a few 2012 gathering of Silicon Valley executives at which President Obama requested Steve Jobs what it could take to get Apple to make iPhones in the US. So as to get ChatGPT to offer a response that clearly concerned copying of a Instances article, the Instances prompted ChatGPT with the primary 237 phrases of the article. ChatGPT’s response included the following 364 phrases of that very same article.
This way of prompting ChatGPT will not be consultant of how most individuals use it. If prompted with the query “Why doesn’t Apple make iPhones in the US?” ChatGPT offers a completely totally different response that doesn’t infringe that 2012 Instances article and seems to be a typical instance of ChatGPT prose – easy, scientific, nicely organized with no persona. In different phrases, what you’d count on of a robotic.
The Criticism additionally experiences having a consumer immediate ChatGPT by saying that it was paywalled out of studying a particular article and asking it to kind out the primary paragraph. ChatGPT cheerfully obliged. When requested for the following paragraph, ChatGPT responded by offering the third paragraph of the article. Criticism at ¶104. One such occasion concerned an article concerning the current Hamas invasion of Israel, not some long-ago archived article. Criticism at ¶112. This poses an actual chance that customers may successfully learn the Instances with out visiting its web site or utilizing its app.
The Criticism additionally describes “artificial search outcomes” by which Bing, powered by AI, returns searches of current information occasions that quote massive parts of Instances articles nearly verbatim. Not like a standard search end result, the artificial output doesn’t embody a distinguished hyperlink that sends customers to The Instances’s web site. Criticism at ¶114.
Is a Statutory License the Reply?
AI builders declare to be on the cusp of a significant societal advance. Content material house owners declare that that is solely made attainable by the exploitation of their work, exploitation which may or won’t be honest use. This example appears to name for a authorized framework that rewards publishers for his or her efforts however encourages the event of LLMs. Fairly than depend on a courtroom’s coin flip as as to if using the copyrighted work to coach LLMs is honest use, it could be higher to develop a licensing mechanism that rewards publishers with out subjecting AI builders to large statutory damages when the first functions and makes use of of the LLM don’t contain displacing content material house owners and their rights.
Regulatory Developments Outdoors of the US.
In 2019, the European Parliament and the Council of the EU issued directive 2019/790 on copyright and associated rights within the Digital Single Market. That directive licensed analysis organizations to hold out scientific analysis utilizing textual content and knowledge mining (“TDM”) of works to which they’ve lawful entry. It requires these organizations to retailer the textual content and knowledge with “applicable ranges of safety.” Different organizations have been additionally licensed to interact in TDM, however with the qualification that copyright house owners might choose out by, for instance, offering a machine-readable discover of reservation of rights in an internet publication. Related legal guidelines have been enacted within the UK, Singapore and Japan.
The desire given to analysis organizations – which aren’t topic to the opt-out mechanism that applies to industrial organizations engaged in TDM – has given rise to “knowledge cleaning”, by which a non-profit group engages in TDM and makes its knowledge set out there to industrial enterprises. Content material house owners naturally discover this apply to be abusive.
The EU is now creating additional tips for knowledge mining performed to coach LLMs. On February 2, 2024, a committee of the European Parliament revealed a provisional agreement proposing that every one AI fashions in use within the EU “make publicly out there a sufficiently detailed abstract of the content material used for coaching the overall function mannequin.” The abstract would listing the primary knowledge units that went into coaching the mannequin and supply a story rationalization about different knowledge sources used. This falls wanting a statutory license regime, nonetheless, since copyright house owners would then have the flexibility, below EU directive 2019/790, to choose out of being included within the coaching set of an LLM.
U.S. Developments
Statutory license schemes exist already in the US – together with one directed to the digital transmission of music. The Librarian of Congress now appoints a three-judge panel, the Copyright Royalty Board, which determines and adjusts royalty charges for such transmissions. See 17 USC §801 at seq. This permits corporations to broadcast music with out acquiring licenses from every copyright proprietor. As a substitute, the broadcaster experiences its use of the music to the copyright workplace and pays the required royalty right into a fund that’s then distributed to the rights holders of the music that was broadcast. Thus far, over $10 billion has been distributed on this method.
An identical mechanism might be established to facilitate using knowledge mining of newspaper content material for the aim of coaching LLMs. Such a system may require the house owners of the fashions to establish the content material that was used to coach the mannequin and to comply with pay royalties on the charge established by the Copyright Royalty Board, which might then trigger the funds to be remitted to the related publishers. Whereas such a system would deprive information organizations of the chance to barter individually for the rights to their content material, it may relieve them of the chance {that a} judicial discovering of honest use would deprive them of any income from LLMs.
On August 30, 2023, the U.S. Copyright Workplace asked for comment on a number of questions involving AI. Amongst them have been questions on copyright licensing:
Ought to Congress think about establishing a obligatory licensing regime?? … What actions ought to the license cowl, what works could be topic to the license, and would copyright house owners have the flexibility to choose out? How ought to royalty charges and phrases be set, allotted, reported and distributed?
Nearly all of the feedback obtained have come from content material creators or organizations representing them. As you would possibly count on, these feedback specific opposition to a obligatory license and specific with confidence the conclusion that utilizing TDM for LLM coaching will not be honest use. A number of feedback quote a comment made by Marybeth Peters, then the Register of Copyrights, in 2005: “The Copyright Workplace has lengthy taken the place that statutory licenses must be enacted solely in distinctive instances, when {the marketplace} is incapable of working.”
Nevertheless, not all opponents of a statutory license see it the identical method. The Pc & Communications Business Affiliation had this to say: “Congress shouldn’t think about establishing a obligatory licensing regime. There isn’t any principled foundation for establishing such a regime. Simply as a reader doesn’t have to pay for studying from a guide, an AI system shouldn’t need to pay for studying from content material posted on an internet site.”
In mild of the damaging response to the notion of a statutory license, it appears unlikely that one will emerge until and till the honest use query is settled in courtroom. Nevertheless, if the courts discover in favor of the AI builders, the tide of opinion will probably shift in favor of statutory reform. That reform may merely exclude coaching of LLMs from honest use; or it may try to bridge the divide between content material house owners and AI builders by enacting a statutory scheme of obligatory licenses.
Such a system would contain complexities not present in digital music broadcasting, together with:
- Hallucinations, or LLM output that that appears sensible however is totally fabricated. The Instances’ Criticism offers examples of “information” attributed to the Instances that it by no means reported and which can be merely unfaithful
- Income loss ensuing from lead era created by AI however originating from a writer’s content material
- Lack of subscription income that will come up if AI fashions displace publishers as sources of knowledge by, for instance, reproducing memorized content material that’s behind paywalls
- The necessity to require creators of LLMs to reveal the info units behind their coaching methods
- Variations between forms of content material – information, pictures and music have totally different qualities that will require regulatory distinctions.
Briefly, a statutory license on this realm will not be probably quickly, however it could turn out to be mandatory if the courts discover that coaching LLMs on copyrighted materials is honest use. By then, steering from the EU and different jurisdictions contemplating this problem could also be instructive.
Picture Supply: Deposit Pictures
Creator: maxkabakov
Picture ID: 35878167